본 포스팅은 Ian Goodfellow 등 2인이 저술한 심층학습(Deep Learning Adaptive Computation and Machine Learning)및 오일석 저술의 기계학습, 사이토 고키 저술의 밑바닥부터 시작하는 딥러닝 등을 기반으로 작성합니다.
이번 포스팅에서는 순환 신경망에 대해서 이해해보죠.
순환신경망은 순차적인 자료를 처리하는 신경망의 한 종류입니다. 합성곱 신경망은 이미지와 같이 격자 형태로 구현된 입력을 처리하는데 유리했죠. 순환신경망은 순차열(Sequence), 즉 순서가 존재하는 입력을 처리하는데 유리합니다.
0. RNN
RNN의 Recurrent는 라틴어에서 온 말인데, "순환하다"라는 뜻을 가집니다. RNN은 결국 직역하면 순환하는 신경망이 됩니다. 이 순환의 의미를 이해해봅시다. 순환이란 "반복해서 되돌아감"이라고 이해하면 쉽습니다. 어느 한 지점에서 시작해, 시간을 지나서 원래 장소로 돌아오는 것이 바로 순환입니다. 중요한 것은 순환을 위해서는 "닫힌 경로"가 필요하다는 사실입니다.
바로 이 닫힌 경로(순환하는 경로)가 RNN의 특징입니다. 왼쪽 그림을 보시면 닫힌 경로가 보일 것입니다.
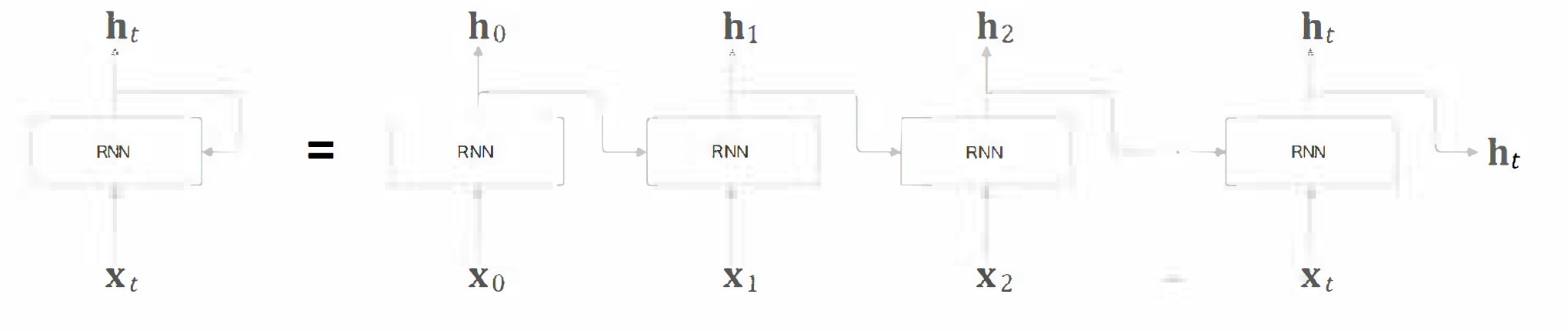
그리고 왼쪽 그림을 펼치면 오른쪽 그림으로도 나타낼 수 있습니다.
그러면 순환의 가장 큰 장점은 무엇일까요? 순환의 가장 큰 장점은 기존의 학습한 정보들을 저장해 이를 다시 활용할 수 있다는 점입니다. 순환 경로를 따라서 데이터를 계층 안에서 순환시키고, 과거의 정보를 기억해 이를 최신 데이터로 갱신시키는 것입니다. RNN이 시계열 데이터나 텍스트 데이터를 처리하는데 강한 이유가 바로 여기에 있습니다.
1. 매개변수 공유
이전 포스팅에서 매개변수 공유에 대해서 설명해드렸죠. 매개변수 공유란, 모형 속 둘 이상의 함수에 같은 매개변수를 사용하는 것이고, 이를 통해 여러 샘플들을 모델링하고 일반화하는데 효율적이라고 말씀드렸습니다. 이를 순환신경망에도 똑같이 적용할 수 있습니다. 만일 각 값에 대해서 매개변수를 따로따로 둔다고 하면, 훈련 중에 경험하지 못한 길이의 순차열에 대해서는 일반화 성능이 떨어지고, 다른 시간과 다른 순차열 길이에서도 공유할 수 없습니다. 예로 들어보죠.
"작년에, 일본 훗카이도에 온천 여행을 갔다왔어."
"일본 훗카이도에 온천 여행을 작년에 갔다왔어."
만일 여기서 언제 일본 훗카이도에 갔는지를 파악해야 한다고 합시다. 그러면 "작년에" 라는 단어가 이 과제의 핵심 키워드이고, 그 위치와 무관하게 중요하게 판단되어야 합니다. 매개변수를 공유하지 않으면, 입력 특징마다 개별적인 매개변수가 주어질 것이고, 각 위치에서의 모든 언어 규칙을 배워야 하므로 비효율적입니다. 매개변수를 공유하게 됨으로서 순서마다 같은 가중치를 공유하므로 효율적입니다.
2. RNN의 구조

RNN은 총 4개의 층으로 이루어진다고 보시면 됩니다.
1. Embedding 계층 : 텍스트와 같은 입력값을 벡터화하는 계층
2. RNN 계층 : 은닉 상태를 위층과 다음 시각의 RNN 층으로 전달
3. Affine 계층 : Fully-Connected Layer로 행렬곱 연산 수행
4. Softmax 계층 : Softmax 활성화 함수를 이용해 확률분포를 추정
위 그림은 RNN이 동작하는 방식을 도식화한 것입니다.
1. x라는 입력값을 받는다.
2. h라는 은닉층을 통과해 o라는 예측값을 얻어낸다.
3. 이를 실제 정답값인 y와 비교해 Loss값인 L을 계산해낸다.
중요한 포인트는 은닉층이 서로 연결되어있고, 은닉상태를 위층과 옆의 다음 시각 RNN 층에도 전달한다는 점입니다.
3. RNN의 동작 방식 예시
RNN의 동작 예시를 통해 좀더 이해해보도록 하겠습니다. RNNLM, 즉 RNN으로 만든 언어 모델로 설명드리죠. 처음 입력에 You 라는 값을 입력받았습니다. 그리고 Embedding 층과 RNN, Affine, Softmax 층을 통과해 'Say'가 그 다음에 나올 확률이 가장 높다고 판단했습니다. 그리고 단어 ID 1번에서의 RNN 계층에 주목해봅시다. RNN 계층에서는 'Say'라는 단어의 벡터값과 함께 이전 시간 RNN 계층에서 'You'라는 단어의 벡터값을 받습니다. 결국 이 계층에서는 'You Say'라는 단어의 벡터값을 이용해 다음 단어를 예측하는 셈인거죠.
RNN 계층은 결국 과거에서부터 현재로까지의 데이터를 누적하고, 과거 정보를 인코딩해 저장하는 형태인 것입니다.
'심층학습 > Natural Language Processing' 카테고리의 다른 글
| Sequencial Model (0) | 2023.11.24 |
|---|---|
| 순환 신경망(Recurrent Neural Network) - Teacher Forcing & BPTT (0) | 2022.03.12 |

