1. Sequencial Model
Sequencial Data, 순차 데이터는 객체들이 특정 순서를 가진 형태의 데이터입니다. 고로, 객체의 순서가 특성을 나타내는 중요한 요소입니다. 이러한 종류의 데이터는 많죠. 매일매일 요동치는 주가 데이터도 그 예고, 애플워치에서 측정한 나의 심장 박동 데이터도, DNA 염기서열도 순차 데이터의 일종입니다. 그리고 가장 대표적인 예시는 바로 글과 문장이죠.
자 그러면 이러한 글과 같은 Sequencial 데이터를 다루는 모델이 어려운 이유를 생각해보죠. 가장 큰 이유는 모델이 받아들이는 입력의 차원을 알 수 없다는 것입니다. 이미지의 경우 고정된 크기의 Input을 통해 고정된 크기의 Output이 나옵니다. 앞 포스팅 CNN을 참고하시면 쉽습니다. 하지만, 말은 얼마나 길어질 지 모릅니다. 박찬호 선수와 같은 투머치 토커의 말씀도 Input으로 들어올 수 있죠.
그리고 두 번째는 순서가 데이터의 특성을 나타내다보니, 순서에 대한 정보가 변조될 경우 데이터의 의미를 잃을 수 있음이 있습니다. 이러한 문제들을 극복해나가는 방법들이 아래 나올 모델들입니다.
1-1. Autoregressive Model and Markov Model

이 것은 과거 TimeSpan을 미리 설정해 둔 뒤, 그 TimeSpan 안에 해당하는 정보만 취하는 것입니다. 간단하게 이야기해서 Timespan을 2로 잡으면, 2번째 전 상황만 보고 나머지는 버린다. 이거죠.

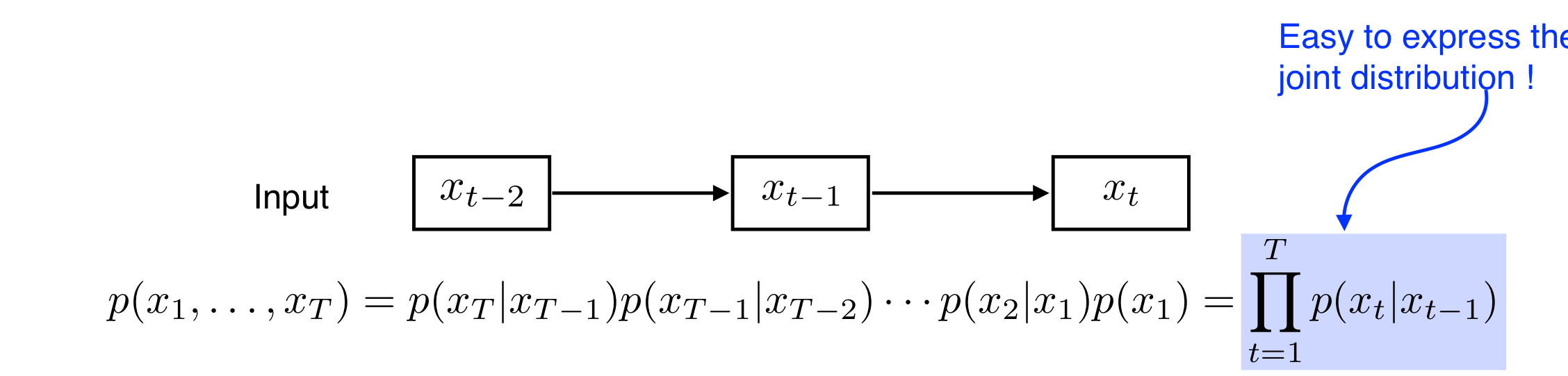
그리고 Markov 모델은 바로 직전의 상황만 본다가 핵심입니다. 현재 상황은 바로 전 상황에만 의존적이며, 과거 t-1번째 상황은 t-2번째 상황에만 의존적이라는 가정을 하고 분석하는 거죠. 이렇게 되면 모델의 크기나 Parameter 수를 낮출 수는 있지만, 과거의 많은 정보는 버려지겠네요.
1-2. Latent Autoregressive Model

연구자들은 과거의 많은 정보를 가져가면서도, 그래도 모델 크기는 너무 키우지 않으려고 이러한 방법을 생각해냅니다. hidden state를 통해 과거의 정보를 요약하고, 이후 time step을 이 hidden state에 의존하는 것입니다. 이러한 방식으로 대표적인 것이 바로 RNN의 단점을 보완한 LSTM입니다. 일단 이 이야기는 나중에 하는 걸로 하죠.
'심층학습 > Natural Language Processing' 카테고리의 다른 글
| 순환 신경망(Recurrent Neural Network) - Teacher Forcing & BPTT (0) | 2022.03.12 |
|---|---|
| 순환 신경망(Recurrent Neural Network) - 개요 (0) | 2022.03.12 |

